调优
大约 6 分钟
调优
基准性能
确认Redis实例是否变慢了
基准性能就是指 Redis 在一台负载正常的机器上,其最大的响应延迟和平均响应延迟分别是怎样的
Redis 在不同的软硬件环境下,它的性能是各不相同的。
- 在相同配置的服务器上,测试一个正常 Redis 实例的基准性能
- 找到你认为可能变慢的 Redis 实例,测试这个实例的基准性能
- 如果你观察到,这个实例的运行延迟是正常 Redis 基准性能的 2 倍以上,即可认为这个 Redis 实例确实变慢了
实例的响应延迟情况
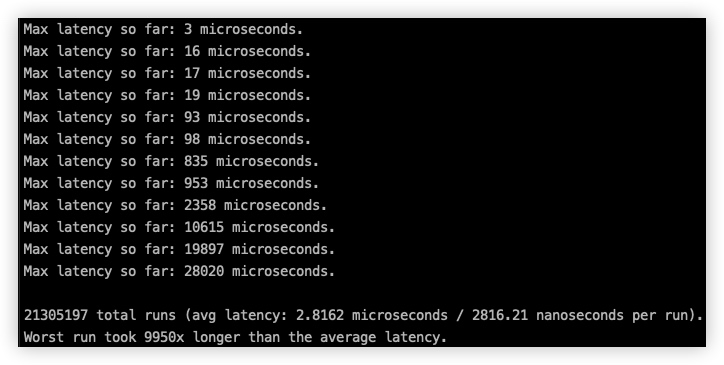
- 60 秒内的最大响应延迟
redis-cli -h x.168.0.x -p 6379 --intrinsic-latency 60
60 秒内的最大响应延迟为 28020 微秒(28.02毫秒)
查看一段时间内 Redis 的最小、最大、平均访问延迟, 每间隔 1 秒
redis-cli -h x.168.0.x -p 6379 --latency-history -i 1
慢日志
使用复杂度过高的命令,导致查询变慢
慢日志配置(命令)
- 命令执行耗时超过 5 毫秒,记录慢日志
CONFIG SET slowlog-log-slower-than 5000
- 只保留最近 500 条慢日志
CONFIG SET slowlog-max-len 500
- 命令执行耗时超过 5 毫秒,记录慢日志
获取慢日志配置
config get *slowlog*获取慢日志 最近5条
slowlog get 5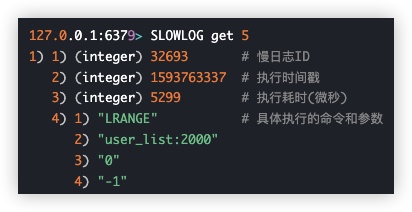
通过查看慢日志,我们就可以知道在什么时间点,执行了哪些命令比较耗时。
Redis 命令有以下特点,那么有可能会导致操作延迟变大
- 经常使用 O(N) 以上复杂度的命令,例如 SORT、SUNION、ZUNIONSTORE 聚合类命令
- 使用 O(N) 复杂度的命令,但 N 的值非常大
解决办法
- 尽量不使用 O(N) 以上复杂度过高的命令,对于数据的聚合操作,放在客户端做
- 执行 O(N) 命令,保证 N 尽量的小(推荐 N <= 300),每次获取尽量少的数据,让 Redis 可以及时处理返回
Big Key
简单命令出现在慢日志中
怀疑你的实例否写入了 bigke
BigKey
- Redis 在写入数据时,需要为新的数据分配内存
- 相对应的,当从 Redis 中删除数据时,它会释放对应的内存空间。
- 如果一个 key 写入的 value 非常大,那么 Redis 在分配内存时就会比较耗时。
- 同样的,当删除这个 key 时,释放内存也会比较耗时,
- Redis 在写入数据时,需要为新的数据分配内存
扫描 bigkey
- 进行 bigkey 扫描时,Redis 的 OPS 会突增
- 为了降低扫描过程中对 Redis 的影响,最好控制一下扫描的频率
- 指定 -i 参数即可
- 它表示扫描过程中每次扫描后休息的时间间隔,单位是秒
- 为了降低扫描过程中对 Redis 的影响,最好控制一下扫描的频率
- 进行 bigkey 扫描时,Redis 的 OPS 会突增
redis-cli -h x.168.0.x -p 6379 --bigkeys -i 0.01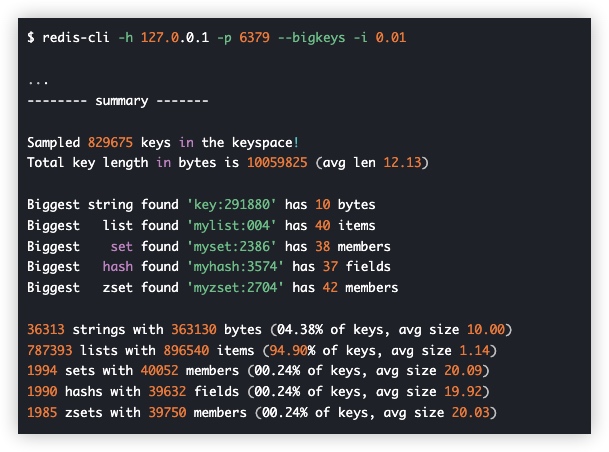
优化
- 避免写入 bigkey
- 删除替代
- Redis 是 4.0 以上版本,用 UNLINK 命令替代 DEL
- 可以把释放 key 内存的操作,放到后台线程中去执行,从而降低对 Redis 的影响
- Redis 是 6.0 以上版本,可以开启 lazy-free 机制(lazyfree-lazy-user-del = yes),在执行 DEL 命令时,释放内存也会放到后台线程中执行
- Redis 是 4.0 以上版本,用 UNLINK 命令替代 DEL
- 避免使用 bigkey 在很多场景下,依旧会产生性能问题,如数据过期、数据淘汰、透明大页等
集中过期(缓存雪崩)
缓存同一时间大面积的失效
过期策略
- 被动过期
- 访问key时判断是否过期,过期删除
- 主动过期
- Redis内部维护了定时任务,默认每隔 100 毫秒(1秒10次)
- 会从全局的过期哈希表中随机取出 20 个 key,然后删除其中过期的 key
- 如果过期 key 的比例超过了 25%,则继续重复此过程
- 直到过期 key 的比例下降到 25% 以下,或者这次任务的执行耗时超过了 25 毫秒,才会退出循环
- Redis内部维护了定时任务,默认每隔 100 毫秒(1秒10次)
- 被动过期
主动过期方式,Redis 主线程中执行
- 存在可能大量删除过期key的操作
- 此时应用程序访问会出现等待的情况
- 造成Redis 延时
- 如果是Big key会更耗时
分析排查
- 业务代码,是否存在集中过期 key 的逻辑
- 一般集中过期使用的是 expireat / pexpireat 命令,你需要在代码中搜索这个关键字。
- 运维监控
INFO命令- expired_keys 情况,累计删除过期 key 的数量,短时间内出现了突增
- 业务代码,是否存在集中过期 key 的逻辑
处理
- 集中过期 key 增加一个随机过期时间,把集中过期的时间打散,降低 Redis 清理过期 key 的压力
- 如果你使用的 Redis 是 4.0 以上版本,可以开启 lazy-free 机制,当删除过期 key 时,把释放内存的操作放到后台线程中执行,避免阻塞主线程
lazyfree-lazy-expire yes
缓存击穿
一个热点 key 过期或被删除后
- 导致线上原本能命中该热点 key 的请求
- 瞬间大量地打到数据库上,最终导致数据库被击垮。
解决办法
- 检查业务代码
- 是否需要过期,或过期策略修改
- 如无需过期,确保不被删除
- 检查业务代码
缓存穿透
- 客户端请求缓存和数据库中不存在的数据,导致所有的请求都打到数据库上。
- 做好参数校验,对于不合理的参数要及时 return 结束
- 对于后端来说,要有互不信任原则
- 对于查不到数据的 key,也将其短暂缓存起来。
- 减轻数据库压力
- 后期排查原因(如非法数据,可做参数校验或请求屏蔽)
- 提供一个能迅速判断请求是否有效的拦截机制
- 比如布隆过滤器,Redis 本身就具有这个功能。
- 布隆过滤器???
- 做好参数校验,对于不合理的参数要及时 return 结束
业务可靠性
- Redis高可用
- 主从 + 哨兵
- 集群
- 减少缓存依赖,如使用本地缓存Guava等
- 业务降级
- 如 限流 处理
内存上限
- Redis 实例设置了内存上限 maxmemory,同时设置一个数据淘汰策略
- 内存达到了 maxmemory 后,每次写入新数据,操作延迟变大了
- 当 Redis 内存达到 maxmemory 后,每次写入新的数据之前,Redis 必须先从实例中踢出一部分数据,让整个实例的内存维持在 maxmemory 之下,然后才能把新数据写进来。
- 踢出旧数据的逻辑也是需要消耗时间的,而具体耗时的长短,要取决于你配置的淘汰策略
- 一般最常使用的是 allkeys-lru / volatile-lru 淘汰策略
allkeys-lru:不管 key 是否设置了过期,淘汰最近最少访问的
keyvolatile-lru:只淘汰最近最少访问、并设置了过期时间的
allkeys-random:不管 key 是否设置了过期,随机淘汰 key
volatile-random:只随机淘汰设置了过期时间的 key
- 解决
- 避免big key
- 更换淘汰策略,如 随机淘汰比LRU要快很多 (视业务情况调整)
- 拆分实例,把淘汰 key 的压力分摊到多个实例上
- Redis 4.0 以上版本,开启 layz-free 机制,把淘汰 key 释放内存的操作放到后台线程中执行
lazyfree-lazy-eviction yes
网络带宽过载
- 如果网络 IO 存在瓶颈,那么也会严重影响 Redis 的性能。
??? fork耗时严重
??? 开启内存大页
??? 开启AOF
??? 绑定CPU
??? 使用Swap
??? 碎片整理
参考
- pdai.tech Redis进阶 - 性能调优:Redis性能调优详解
- 二哥的Java进阶之路简单聊聊缓存雪崩、穿透、击穿