配置调优
大约 5 分钟
配置调优
部署配置
- 配置文件
- /etc/my.cnf
- /etc/my.cnf.d/server.cnf
- 主要配置
- basedir:安装目录
- datadir:数据目录
- socket:指定socket文件位置路径
.sock
- 内部通信使用的socket接口,比3306快
.pid
- mysql进程ID
查询缓存
- 写入频繁的数据库,不要开查询缓存
- 禁掉查询缓存:# query_cache_size=1M(注释掉即可)
连接数
- open_files_limit 打开文件数
- max_connections 最大连接数 默认100,MySQL服务器允许的最大连接数16384
- max_connect_errors 设置每个主机的连接请求异常中断的最大次数,当超过该次数,MYSQL服务器将禁止host的连接请求
慢查询
- slow_query_log 是否开启慢查询日志,1表示开启,0表示关闭。
- slow-query-log-file 日志路径,可以不设置该参数,系统则会默认给一个缺省的文件host_name-slow.log
- long_query_time 慢查询阈值,当查询时间多于设定的阈值时,记录日志。
- log_output 日志存储方式。log_output='FILE'表示将日志存入文件,默认值是'FILE'。
- log_output='TABLE'表示将日志存入数据库,这样日志信息就会被写入到mysql.slow_log表中。MySQL数据库支持同时两种日志存储方式,配置的时候以逗号隔开即可,如:log_output='FILE,TABLE'。
- 日志记录到系统的专用日志表中,要比记录到文件耗费更多的系统资源,因此对于需要启用慢查询日志,又需要能够获得更高的系统性能,那么建议优先记录到文件。
日志:尽量不开启日志尤其是写入频繁的日志,以免影响性能。
- 错误日志:log-error=/var/log/mysql/err.log
- 查询日志 general_log=on ;general_log_file=/var/log/mysql/qeury.log
- 慢查询 slow_query_log = on;slow-query-log-file= /var/log/mysql/slow.log
- long_query_time=10 慢查询时间 默认10秒
- 二进制日志:
- 记录数据变更
- 如主从模式需要开始
- 开启:
- server_id=1 # 配server id
- log_bin = mysql-bin # 开启bin log /var/log/mysql/bin
- binlog_format = ROW # bin log模式
- ROW 基于行
- Statement 基于sql
- MIXED 混合模式复制
SQL优化配置
索引
- 索引:提高查询效率;索引是为了加速对表中数据行的检索而创建的一种分散存储的数据结构。
- 索引类型
- 按字段分
- 主键索引
- 主键字段,一张表只有一个
- 不允许为空,值唯一
- 唯一索引
- 字段上定义,或单独定义,或建表后定义
- name varchar(8) unique key
- unique key $keyname (column1, column2),
- create index index_name on table_name(index_column_1,index_column_2,...);
- 普通索引(单列索引、联合索引(复合索引))
- 通过普通字段创建索引
- 建表 index [$keyName] (column1,column2,...)
- create index indexName on table_name(index_column_1,index_column_2,...);
- 前缀索引
- 前缀索引是指对字符类型字段的前几个字符建立的索引,而不是在整个字段上建立的索引,前缀索引可以建立在字段类型为 char、 varchar、binary、varbinary 的列上。
- INDEX(column_name(length))
- 主键索引
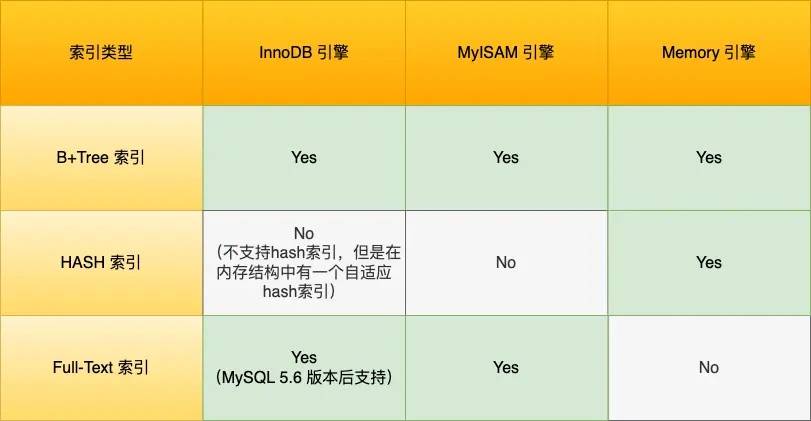
- 数据结构 ???
- B+Tree 索引 ,Mysql 采用较多的
- 按字段分
索引失效
- 左或者左右模糊匹配, like %xx 或者 like %xx%
- 查询条件中对索引列做了计算、函数、类型转换操作: where id + 1 = 10
- 联合索引要能正确使用需要遵循最左匹配原则,也就是按照最左优先的方式进行索引的匹配,否则就会导致索引失效。
- 在 WHERE 子句中,如果在 OR 前的条件列是索引列,而在 OR 后的条件列不是索引列,那么索引会失效
执行计划
- explain select * from demo_user where user_name = 'zhangsan' and deleted = 0;
- type 扫描类型
- All(全表扫描);
- index(全索引扫描);
- range(索引范围扫描);
- ref(非唯一索引扫描);
- eq_ref(唯一索引扫描);
- const(结果只有一条的主键或唯一索引扫描)。
- type 扫描类型
[
{
"id": 1,
"select_type": "SIMPLE",
"table": "demo_user",
"partitions": null,
"type": "const", # 数据扫描类型
"possible_keys": # 可能用到的索引
"user_unique,user_name_query",
"key": "user_unique", # 实际用的索引,如果这一项为 NULL,说明没有使用索引;
"key_len": "195", # 索引的长度
"ref": "const,const",
"rows": 1, # 扫描的数据行数
"filtered": 100,
"Extra": null
}
]
使用索引
- 什么时候适用索引
- 字段具有唯一性约束
- 经常用于where查询条件的字段
- 经常用于 GROUP BY 和 ORDER BY 的字段
- 不需要重新排序:建立索引之后在 B+Tree 中的记录都是排序好的
- 不需要索引
- 不用于查询或排序的字段
- 字段中数据大量重复
- 如男 女 性别字段,数据基本分布均匀,MySQL查询优化器发现某个值出现在表的数据行中的百分比很高的时候,它一般会忽略索引,进行全表扫描。
- 表数据太少
- 经常更新的字段
- 索引优化
- 前缀索引优化
- 前几个字符建立的索引,使用前缀索引的目的是为了减少索引占用的存储空间,提升查询效率。
- 局限性:
- order by 就无法使用前缀索引
- 无法把前缀索引用作覆盖索引
- 主键索引最好是自增的
- 索引最好设置为 NOT NULL
- 导致优化器在做索引选择的时候更加复杂,更加难以优化
- NULL 值是一个没意义的值,但是它会占用物理空间
- 前缀索引优化
- 索引使用情况
show status like 'Handler_read%'- Handler_read_key 高 表示索引正在工作
- Handler_read_rnd_next 的值高,则意味着查询运行低效
Mysql调优
单表数据量:2000W行 ???
- 推荐值:超过了这个值可能会导致 B + 树层级更高,影响查询性能。
SQL优化一般步骤
- 查询Mysql统计或监控数据,了解应用情况,如show status,如读写频率,性能
- 查找慢sql
- explan 分析执行计划
- 定位问题,读写效率,查询效率 等
常见sql优化
- 插入大量数据
- 关闭唯一性检查
- 关闭自动提交
- 数据按照主键排序
- group by null 禁止排序
- order by 使用索引提升效率
- 使用 join查询替代 in子查询,可能提升效率,join不需要在内存中创建临时表
- or 查询,每个条件增加索引
- 插入大量数据