JVM
JVM
内存区域
Java 虚拟机在执行 Java 程序的过程中会把它管理的内存划分成若干个不同的数据区域
JDK 1.7
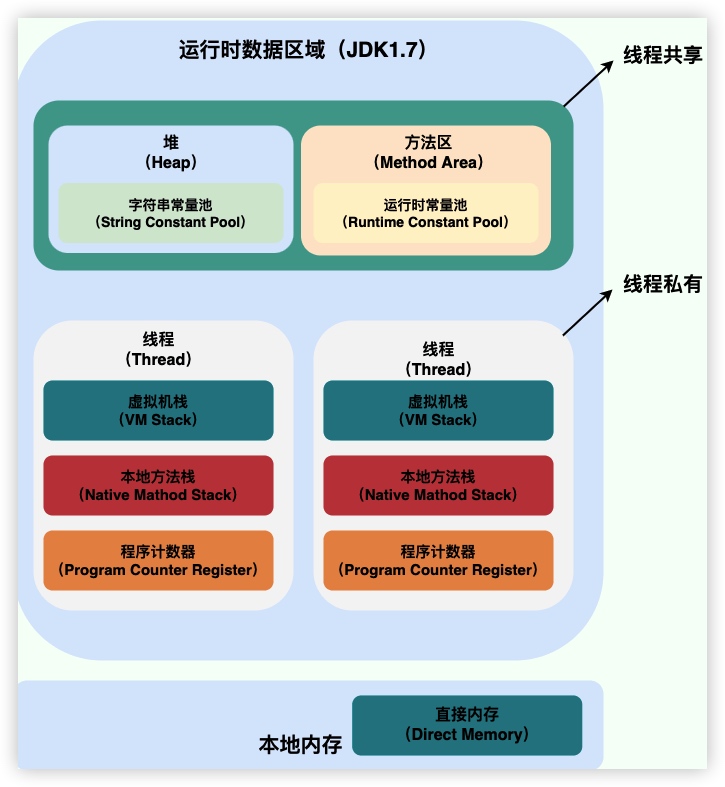
- 运行时数据区域
- 线程共享
- 堆 Heap
- 分代垃圾收集算法
- 新生代
- 老年代
- 永久代
- 字符串常量池 String Constant Pool
- 分代垃圾收集算法
- 方法区 Method Area
- 运行时常量池 Runtime Constant Pool
- 堆 Heap
- 线程私有
- 线程1
- 虚拟机栈 VM Stack
- 虚拟机执行 Java 方法 (也就是字节码)服务
- 本地方法栈 Native Method Stack
- Native 方法
- 程序计数器 Program Counter Register
- 虚拟机栈 VM Stack
- 线程n...
- 线程1
- 线程共享
- 本地内存
- 直接内存 Direct Memory
JDK1.8
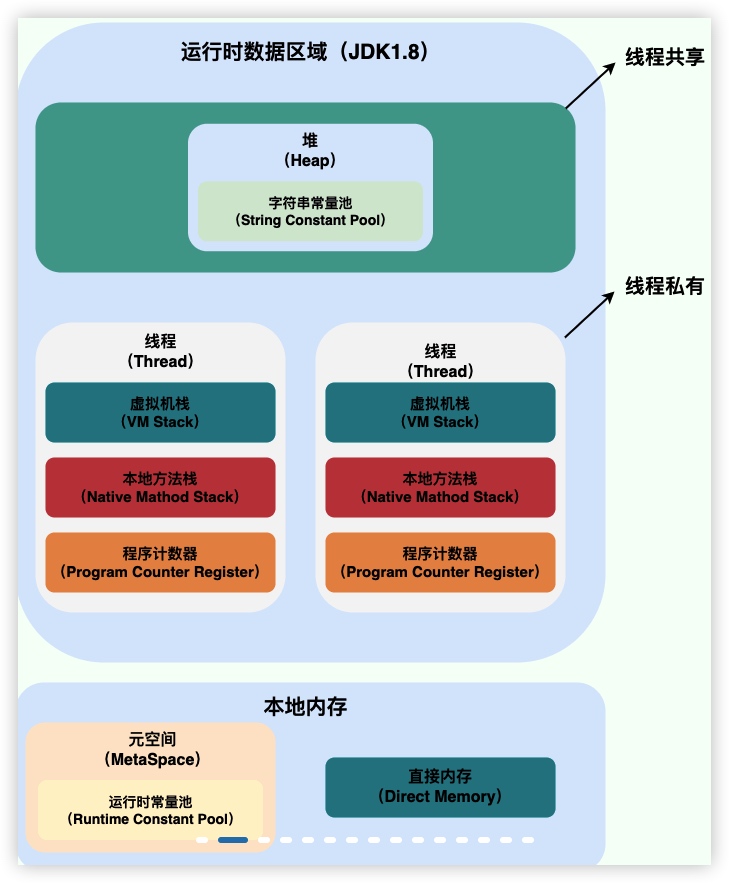
- 运行时数据区域
- 线程共享
- 堆 Heap
- 分代垃圾收集算法
- 新生代
- 老年代
永久代(元空间)
- 字符串常量池 String Constant Pool
- 分代垃圾收集算法
- 堆 Heap
- 线程私有
- 线程1
- 虚拟机栈 VM Stack
- 本地方法栈 Native Method Stack
- 程序计数器 Program Counter Register
- 线程n...
- 线程1
- 线程共享
- 本地内存
- 元空间 Mate Space
- 运行时常量池 Runtime Constant Pool
- 直接内存 Direct Memory
- 元空间 Mate Space
知识点
类文件
- JVM 可以理解的代码就叫做字节码(即扩展名为 .class 的文件)
Class 文件结构

- package cn.hutool.json;
- public class JSONObject extends MapWrapper

- 魔数(Magic Number)
- 每个 Class 文件的头 4 个字节称为魔数(Magic Number)
- Java 规范规定魔数为固定值:0xCAFEBABE。
- Class 文件版本号(Minor&Major Version)
- 常量池(Constant Pool)
- 访问标志(Access Flags)
- 类Or接口,abstract 或 public
- 当前类(This Class)、父类(Super Class)、接口(Interfaces)索引集合
- 字段表集合(Fields)
- 用于描述接口或类中声明的变量。字段包括类级变量以及实例变量,但不包括在方法内部声明的局部变量。
- 方法表集合(Methods)
- 属性表集合(Attributes)
类加载过程
类的生命周期
- 类从被加载到虚拟机内存中开始到卸载出内存为止
- 简单概括为 7 个阶段
- 验证、准备和解析这三个阶段可以统称为连接
- 1、加载(Loading)
- 连接(Linking)
- 2、验证(Verification)
- 3、准备(Preparation)
- 4、解析(Resolution)
- 5、初始化(Initialization)
- 6、使用(Using)
- 7、卸载(Unloading)
类加载过程
- 系统加载 Class 类型的文件主要三步:加载->连接->初始化。
- 连接过程又可分为三步:验证->准备->解析。
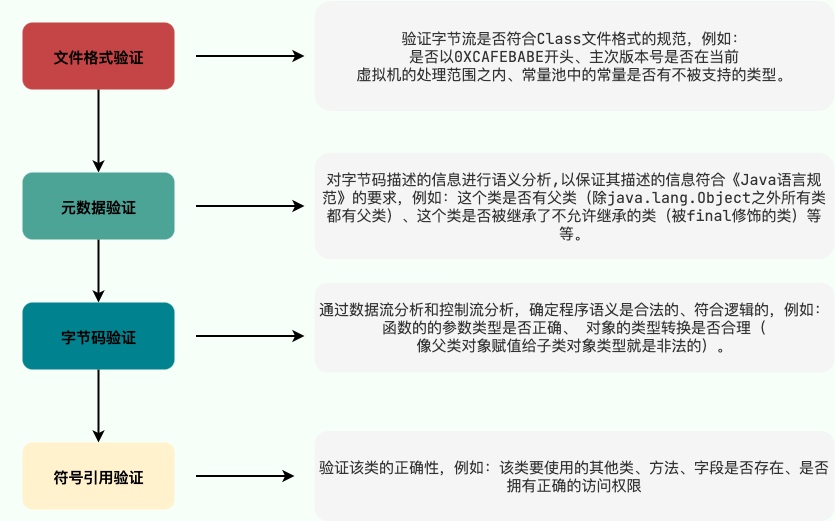
- 加载( 主要通过类加载器完成)
- 通过全类名获取定义此类的二进制字节流。
- 将字节流所代表的静态存储结构转换为方法区的运行时数据结构。
- 在内存中生成一个代表该类的 Class 对象,作为方法区这些数据的访问入口。
- 连接
- 验证(确保 Class 文件的字节流中包含的信息符合《Java 虚拟机规范》的全部约束要求,保证这些信息被当作代码运行后不会危害虚拟机自身的安全。)
- 文件格式验证(Class 文件格式检查)
- 元数据验证(字节码语义检查)
- 字节码验证(程序语义检查)
- 符号引用验证(类的正确性检查)
- 准备,准备阶段是正式为类变量分配内存并设置类变量初始值的阶段,这些内存都将在方法区中分配。
- 解析,是虚拟机将常量池内的符号引用替换为直接引用的过程。 解析动作主要针对类或接口、字段、类方法、接口方法、方法类型、方法句柄和调用限定符 7 类符号引用进行。
- 验证(确保 Class 文件的字节流中包含的信息符合《Java 虚拟机规范》的全部约束要求,保证这些信息被当作代码运行后不会危害虚拟机自身的安全。)
- 初始化
- 初始化阶段是执行初始化方法
<clinit> ()方法的过程,是类加载的最后一步,这一步 JVM 才开始真正执行类中定义的Java 程序代码(字节码)。 - 说明:
<clinit> ()方法是编译之后自动生成的。
- 初始化阶段是执行初始化方法
类卸载
- 卸载类即该类的 Class 对象被 GC。
类加载器
类加载器的主要作用就是加载 Java 类的字节码( .class 文件)到 JVM 中(在内存中生成一个代表该类的 Class 对象)。
加载规则
- JVM 启动的时候,并不会一次性加载所有的类,而是根据需要去动态加载
- 对内存更加友好
- 对于已经加载的类会被放在 ClassLoader 中。在类加载的时候,系统会首先判断当前类是否被加载过。已经被加载的类会直接返回,否则才会尝试加载。也就是说,对于一个类加载器来说,相同二进制名称的类只会被加载一次。
JVM 中内置加载器
- BootstrapClassLoader(启动类加载器),%JAVA_HOME%/lib,主要用来加载 JDK 内部的核心类库
- ExtensionClassLoader(扩展类加载器),%JRE_HOME%/lib/ext,
- AppClassLoader(应用程序类加载器)
- 自定义的类加载器来进行拓展
- 继承 ClassLoader抽象类
- findClass
- loadClass
- 继承 ClassLoader抽象类
- 除了 BootstrapClassLoader 是 JVM 自身的一部分之外,其他所有的类加载器都是在 JVM 外部实现的,并且全都继承自 ClassLoader 抽象类。
- 每个 ClassLoader 可以通过getParent()获取其父 ClassLoader,如果获取到 ClassLoader 为null的话,那么该类是通过 BootstrapClassLoader 加载的。因为BootstrapClassLoader 由 C++ 实现,由于这个 C++ 实现的类加载器在 Java 中是没有与之对应的类的,所以拿到的结果是 null。
双亲委派模型
- 类加载器有很多种,当我们想要加载一个类的时候,具体是哪个类加载器加载呢?这就需要提到双亲委派模型了。
- ClassLoader 类使用委托模型来搜索类和资源
- 双亲委派模型要求除了顶层的启动类加载器外,其余的类加载器都应有自己的父类加载器。
- ClassLoader 实例会在试图亲自查找类或资源之前,将搜索类或资源的任务委托给其父类加载器。
- 打破双亲委派模型方法
- 重写 loadClass() 方法
- 双亲委派模型,加载类时委派给父类加载器去完成(调用父加载器 loadClass()方法来加载类)
堆内存
- Java 世界中“几乎”所有的对象都在堆中分配
- 垃圾收集器管理的主要区域,因此也被称作 GC 堆(Garbage Collected Heap)
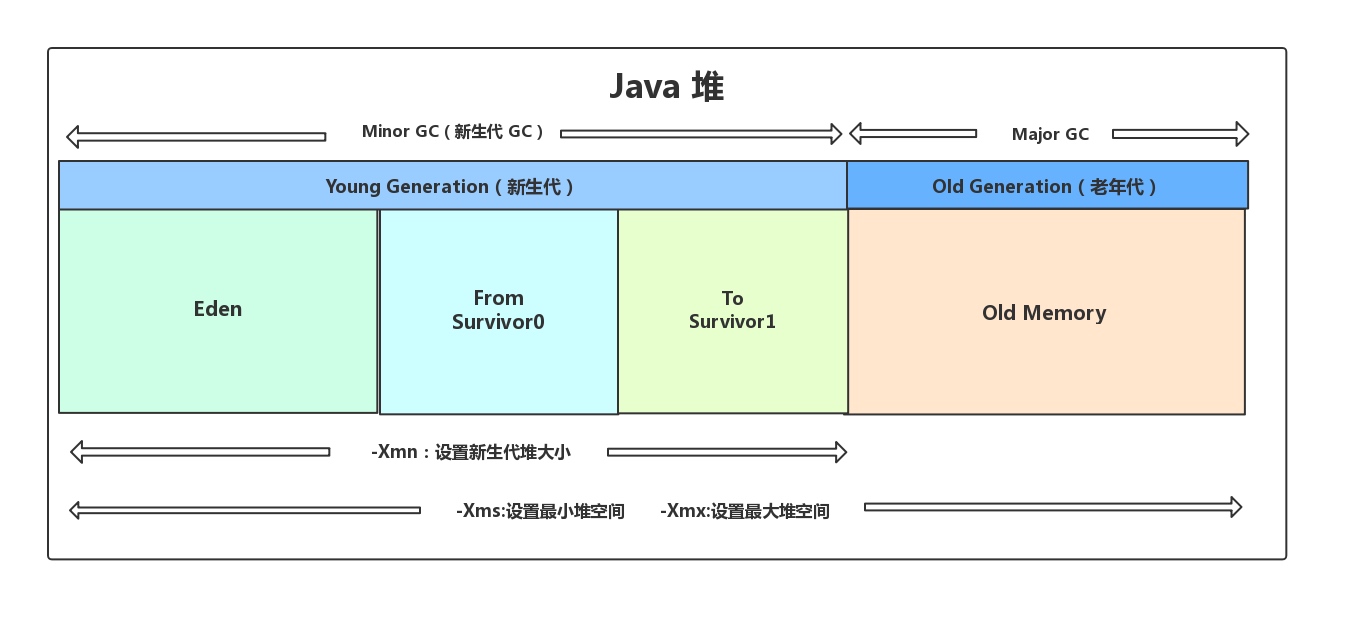
- 堆的大小可调节
- 堆空间
- -Xms 最小
- -Xmx 最大
- 通常设置相同,其目的是为了能够在java垃圾回收机制清理完堆区后不需要重新分隔计算堆区的大小,从而提高性能。
- 默认:
- 初始内存大小:物理电脑内存大小/64
- 最大内存大小:物理电脑内存大小/4
- -Xmn 新生代堆大小
- -XX:NewRatio
- 新生代与老年代在堆结构的占比
- 默认-XX:NewRatio=2,表示新生代占1,老年代占2,新生代占整个堆的1/3
- 可以修改-XX:NewRatio=4,表示新生代占1,老年代占4,新生代占整个堆的1/5
- 新生代与老年代在堆结构的占比
- -xx:SurvivorRatio
- Eden空间和Survivor占比
- 在HotSpot中,Eden空间和另外两个survivor空间缺省所占的比例是8:1:1当然开发人员可以通过选项“-xx:SurvivorRatio”调整这个空间比例
- -Xx:MaxTenuringThreshold
- 新生代过渡到老年代的年龄设置,年龄阀值
- 堆空间
STW
- Stop The World
- 是指在执行垃圾算法时,Java应用程序的其他所有线程都被挂起(除了垃圾回收帮助器之外)
- Java中一种全局暂停现象,全局停顿;
- 所有Java代码停止;native代码可以执行,但不能与JVM交互
- 该现象多半是由于GC引起的;
- 借助 安全点(Safe Point) 加参数排查;
JNI
- Java Native Interface; Java本地方法接口;
- 是Java语言允许Java代码与C、C++代码交互的标准机制;
GC过程
- 新生代GC -> 老年代GC -> Full GC
- 部分收集 (Partial GC):
- 新生代收集(Minor GC / Young GC):只对新生代进行垃圾收集;
- 老年代收集(Major GC / Old GC):只对老年代进行垃圾收集。需要注意的是 Major GC 在有的语境中也用于指代整堆收集;
- 混合收集(Mixed GC):对整个新生代和部分老年代进行垃圾收集。
- 整堆收集 (Full GC):收集整个 Java 堆和方法区。
- JVM在进行GC时,并非每次都对上面三个内存区域一起回收的,大部分时候回收的都是指新生代。
MinorGC
- YGC/新生代GC
- 何时发生Minor GC :当年轻代空间不足时,就会触发MinorGC,这里的年轻代满指的是Eden代满,Survivor满不会引发GC。(每次Minor GC会清理年轻代的内存。)
- Minor GC 特性:频率高,回收速度快。因为大部分对象朝生夕死。
- 是否会引发STW 会,暂停其他用户线程。但是比Major GC (老年代GC)引发的STW影响小。
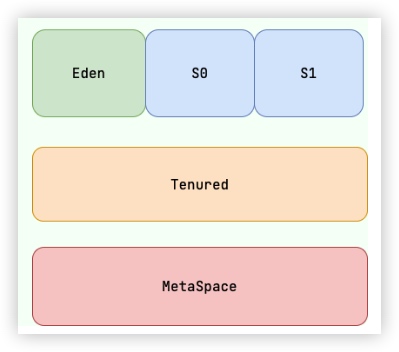
- Eden --> S0 --> S1 --> Tenured/Old
- 当Eden区存满时,会触发一个MinorGC操作
- 年龄 + 1
- Survivor中 超过 阀值(15),晋升老年代
- 动态年龄判定/阀值变动
动态对象年龄判定:Hotspot遍历所有对象时,按照年龄从小到大对其所占用的大小进行累加, 当累加到某个年龄时,所累加的大小超过了survivor区的一半(默认值是 50%,可以通过 -XX:TargetSurvivorRatio=percent 来设置), 则取这个年龄和MaxTenuringThreshold中更小的一个值,作为新的晋升年龄阈值。
内存分配与回收原则
- 对象优先在 Eden 区分配
- Minor GC 时,若对象太大无法进入Survivor空间,通过分配担保机制会将对象放入老年代
- 大对象直接进入老年代
- 需要大量连续内存空间的对象(比如:字符串、数组)
- 旨在避免将大对象放入新生代,从而减少新生代的垃圾回收频率和成本
- 长期存活的对象将进入老年代
- 虚拟机给每个对象一个对象年龄(Age)计数器
- 主要进行 gc 的区域
- 部分收集 Partial GC
- 新生代收集(Minor GC / Young GC)
- 老年代收集(Major GC / Old GC)
- 混合收集(Mixed GC)
- 整堆收集 (Full GC)
- 部分收集 Partial GC
- 空间分配担保
- 空间分配担保是为了确保在 Minor GC 之前老年代本身还有容纳新生代所有对象的剩余空间
死亡对象判断方法
- 引用计数法(主流的虚拟机,都不使用,很难解决对象之间循环引用)
- 每当有一个地方引用它,计数器就加 1;
- 当引用失效,计数器就减 1;
- 任何时候计数器为 0 的对象就是不可能再被使用的
- 可达性分析算法
- GC Roots: 当一个对象到 GC Roots 没有任何引用链相连的话,则证明此对象是不可用的
- 引用类型总结:判定对象的存活都与“引用”有关
- JDK1.2 之前,Java 中引用的定义很传统:如果 reference 类型的数据存储的数值代表的是另一块内存的起始地址,就称这块内存代表一个引用。
- JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引用、软引用、弱引用、虚引用四种(引用强度逐渐减弱)
- 强引用:垃圾回收器绝不会回收它
- 软引用:内存空间足够,垃圾回收器就不会回收它
- 弱引用:不管当前内存空间足够与否,都会回收它的内存
- 虚引用:任何时候都可能被垃圾回收
- 如何判断一个常量是废弃常量?
- 运行时常量池主要回收的是废弃的常量。
- 如字符串,无String对象引用该字符串常量时,内存回收时会清理;
- 如何判断一个类是无用的类?
- 方法区主要回收的是无用的类。要同时满足下面 3 个条件
- 该类所有的实例都已经被回收,也就是 Java 堆中不存在该类的任何实例。
- 加载该类的 ClassLoader 已经被回收。
- 该类对应的 java.lang.Class 对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
- 仅仅是“可以”,而并不是和对象一样不使用了就会必然被回收。
- 方法区主要回收的是无用的类。要同时满足下面 3 个条件
垃圾回收算法
- 标记-清除算法
- 复制算法
- 标记-整理算法
- 分代收集算法
- 当前虚拟机的垃圾收集都采用分代收集算法
- 我们就可以根据各个年代的特点选择合适的垃圾收集算法
垃圾收集器
- 收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。
- 根据具体应用场景选择适合自己的垃圾收集器
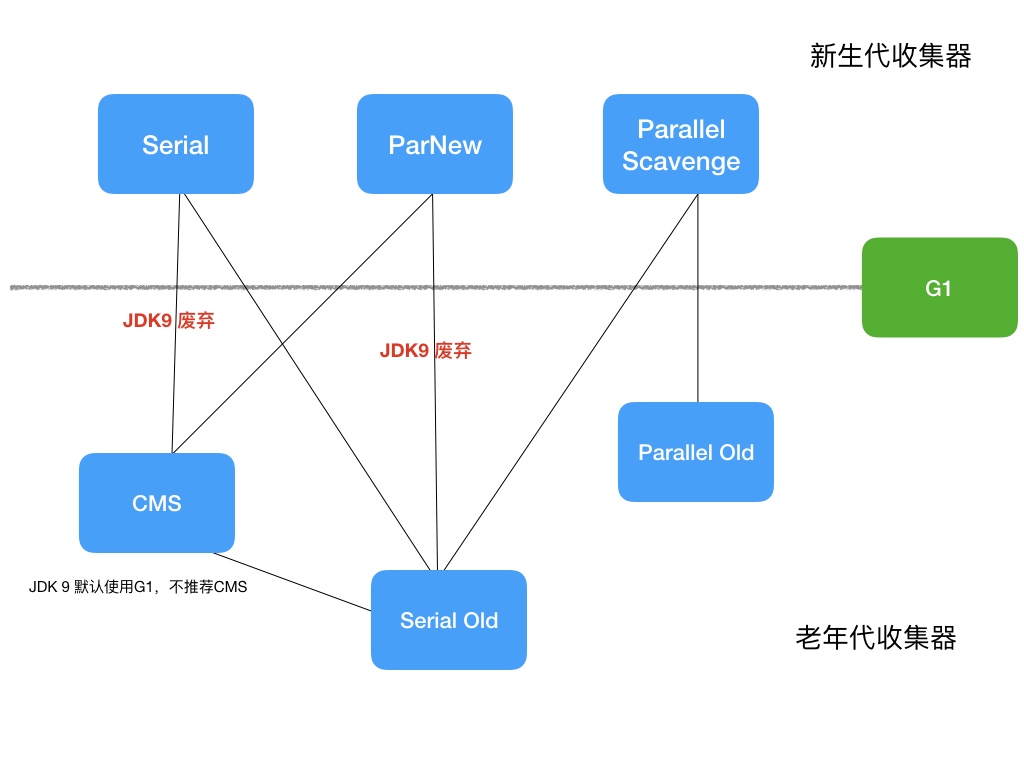
- JDK 默认垃圾收集器(使用 java -XX:+PrintCommandLineFlags -version 命令查看)
- JDK 8:Parallel Scavenge(新生代)+ Parallel Old(老年代)
- JDK 9 ~ JDK20: G1
- JDK 默认垃圾收集器(使用 java -XX:+PrintCommandLineFlags -version 命令查看)
- 新生代回收器
- Serial
- ParNew
- parallel
- 老年代回收器
- Serial Old
- CMS
- Parallel Old
- 新生代和老年代回收器
- G1
- Serial 收集器
- 单线程
- 新生代采用标记-复制算法,老年代采用标记-整理算法。
- 简单而高效(与其他收集器的单线程相比)
- Serial 收集器对于运行在 Client 模式下的虚拟机来说是个不错的选择
- STW
- ParNew 收集器
- Serial 收集器的多线程版本
- 新生代采用标记-复制算法,老年代采用标记-整理算法。
- 运行在 Server 模式下的虚拟机的首要选择
- 它能与 CMS 收集器(真正意义上的并发收集器)配合工作
- Parallel Scavenge 收集器
- 使用标记-复制算法的多线程收集器
- Parallel Scavenge 收集器关注点是吞吐量(高效率的利用 CPU)
- JDK1.8 默认收集器
- Serial Old 收集器
- Serial 收集器的老年代版本,它同样是一个单线程收集器
- Parallel Old 收集器
- Parallel Scavenge 收集器的老年代版本。使用多线程和“标记-整理”算法。在注重吞吐量以及 CPU 资源的场合,都可以优先考虑 Parallel Scavenge 收集器和 Parallel Old 收集器。
- CMS 收集器
- “标记-清除”算法实现的
- CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。它非常符合在注重用户体验的应用上使用。
- HotSpot 虚拟机第一款真正意义上的并发收集器,它第一次实现了让垃圾收集线程与用户线程(基本上)同时工作。
- G1 收集器
- G1 (Garbage-First) 是一款面向服务器的垃圾收集器,主要针对配备多颗处理器及大容量内存的机器. 以极高概率满足 GC 停顿时间要求的同时,还具备高吞吐量性能特征.
- JDK9 开始,G1 垃圾收集器成为了默认的垃圾收集器
- ZGC 收集器
- 与 CMS 中的 ParNew 和 G1 类似,ZGC 也采用标记-复制算法,不过 ZGC 对该算法做了重大改进。
- 在 ZGC 中出现 Stop The World 的情况会更少!
- Java11 的时候 ,ZGC 还在试验阶段。经过多个版本的迭代,不断的完善和修复问题,
- ZGC 在 Java 15 已经可以正式使用了!
OutOfMemoryError
java.lang.OutOfMemoryError: GC Overhead Limit Exceeded:当 JVM 花太多时间执行垃圾回收并且只能回收很少的堆空间时
java.lang.OutOfMemoryError: Java heap space :假如在创建新的对象时, 堆内存中的空间不足以存放新创建的对象, 就会引发此错误。(和配置的最大堆内存有关,且受制于物理内存大小。最大堆内存可通过-Xmx参数配置,若没有特别配置,将会使用默认值
- Java 世界中“几乎”所有的对象都在堆中分配
- 垃圾收集器管理的主要区域,因此也被称作 GC 堆(Garbage Collected Heap)
- 堆的大小可调节
- 堆空间
- -Xms 最小
- -Xmx 最大
- 通常设置相同,其目的是为了能够在java垃圾回收机制清理完堆区后不需要重新分隔计算堆区的大小,从而提高性能。
- 默认:
- 初始内存大小:物理电脑内存大小/64
- 最大内存大小:物理电脑内存大小/4
- -Xmn 新生代堆大小
- -XX:NewRatio
- 新生代与老年代在堆结构的占比
- 默认-XX:NewRatio=2,表示新生代占1,老年代占2,新生代占整个堆的1/3
- 可以修改-XX:NewRatio=4,表示新生代占1,老年代占4,新生代占整个堆的1/5
- 新生代与老年代在堆结构的占比
- -xx:SurvivorRatio
- Eden空间和Survivor占比
- 在HotSpot中,Eden空间和另外两个survivor空间缺省所占的比例是8:1:1当然开发人员可以通过选项“-xx:SurvivorRatio”调整这个空间比例
- -Xx:MaxTenuringThreshold
- 新生代过渡到老年代的年龄设置,年龄阀值
- 堆空间
STW
- Stop The World
- 是指在执行垃圾算法时,Java应用程序的其他所有线程都被挂起(除了垃圾回收帮助器之外)
- Java中一种全局暂停现象,全局停顿;
- 所有Java代码停止;native代码可以执行,但不能与JVM交互
- 该现象多半是由于GC引起的;
- 借助 安全点(Safe Point) 加参数排查;
JNI
- Java Native Interface; Java本地方法接口;
- 是Java语言允许Java代码与C、C++代码交互的标准机制;
GC过程
- 新生代GC -> 老年代GC -> Full GC
- 部分收集 (Partial GC):
- 新生代收集(Minor GC / Young GC):只对新生代进行垃圾收集;
- 老年代收集(Major GC / Old GC):只对老年代进行垃圾收集。需要注意的是 Major GC 在有的语境中也用于指代整堆收集;
- 混合收集(Mixed GC):对整个新生代和部分老年代进行垃圾收集。
- 整堆收集 (Full GC):收集整个 Java 堆和方法区。
- JVM在进行GC时,并非每次都对上面三个内存区域一起回收的,大部分时候回收的都是指新生代。
MinorGC
- YGC/新生代GC
- 何时发生Minor GC :当年轻代空间不足时,就会触发MinorGC,这里的年轻代满指的是Eden代满,Survivor满不会引发GC。(每次Minor GC会清理年轻代的内存。)
- Minor GC 特性:频率高,回收速度快。因为大部分对象朝生夕死。
- 是否会引发STW 会,暂停其他用户线程。但是比Major GC (老年代GC)引发的STW影响小。
- Eden --> S0 --> S1 --> Tenured/Old
- 当Eden区存满时,会触发一个MinorGC操作
- 年龄 + 1
- Survivor中 超过 阀值(15),晋升老年代
- 动态年龄判定/阀值变动
动态对象年龄判定:Hotspot遍历所有对象时,按照年龄从小到大对其所占用的大小进行累加, 当累加到某个年龄时,所累加的大小超过了survivor区的一半(默认值是 50%,可以通过 -XX:TargetSurvivorRatio=percent 来设置), 则取这个年龄和MaxTenuringThreshold中更小的一个值,作为新的晋升年龄阈值。
内存分配与回收原则
- 对象优先在 Eden 区分配
- Minor GC 时,若对象太大无法进入Survivor空间,通过分配担保机制会将对象放入老年代
- 大对象直接进入老年代
- 需要大量连续内存空间的对象(比如:字符串、数组)
- 旨在避免将大对象放入新生代,从而减少新生代的垃圾回收频率和成本
- 长期存活的对象将进入老年代
- 虚拟机给每个对象一个对象年龄(Age)计数器
- 主要进行 gc 的区域
- 部分收集 Partial GC
- 新生代收集(Minor GC / Young GC)
- 老年代收集(Major GC / Old GC)
- 混合收集(Mixed GC)
- 整堆收集 (Full GC)
- 部分收集 Partial GC
- 空间分配担保
- 空间分配担保是为了确保在 Minor GC 之前老年代本身还有容纳新生代所有对象的剩余空间
死亡对象判断方法
- 引用计数法(主流的虚拟机,都不使用,很难解决对象之间循环引用)
- 每当有一个地方引用它,计数器就加 1;
- 当引用失效,计数器就减 1;
- 任何时候计数器为 0 的对象就是不可能再被使用的
- 可达性分析算法
- GC Roots: 当一个对象到 GC Roots 没有任何引用链相连的话,则证明此对象是不可用的
- 引用类型总结:判定对象的存活都与“引用”有关
- JDK1.2 之前,Java 中引用的定义很传统:如果 reference 类型的数据存储的数值代表的是另一块内存的起始地址,就称这块内存代表一个引用。
- JDK1.2 以后,Java 对引用的概念进行了扩充,将引用分为强引用、软引用、弱引用、虚引用四种(引用强度逐渐减弱)
- 强引用:垃圾回收器绝不会回收它
- 软引用:内存空间足够,垃圾回收器就不会回收它
- 弱引用:不管当前内存空间足够与否,都会回收它的内存
- 虚引用:任何时候都可能被垃圾回收
- 如何判断一个常量是废弃常量?
- 运行时常量池主要回收的是废弃的常量。
- 如字符串,无String对象引用该字符串常量时,内存回收时会清理;
- 如何判断一个类是无用的类?
- 方法区主要回收的是无用的类。要同时满足下面 3 个条件
- 该类所有的实例都已经被回收,也就是 Java 堆中不存在该类的任何实例。
- 加载该类的 ClassLoader 已经被回收。
- 该类对应的 java.lang.Class 对象没有在任何地方被引用,无法在任何地方通过反射访问该类的方法。
- 仅仅是“可以”,而并不是和对象一样不使用了就会必然被回收。
- 方法区主要回收的是无用的类。要同时满足下面 3 个条件
垃圾回收算法
- 标记-清除算法
- 复制算法
- 标记-整理算法
- 分代收集算法
- 当前虚拟机的垃圾收集都采用分代收集算法
- 我们就可以根据各个年代的特点选择合适的垃圾收集算法
垃圾收集器
- 收集算法是内存回收的方法论,那么垃圾收集器就是内存回收的具体实现。
- 根据具体应用场景选择适合自己的垃圾收集器
- JDK 默认垃圾收集器(使用 java -XX:+PrintCommandLineFlags -version 命令查看)
- JDK 8:Parallel Scavenge(新生代)+ Parallel Old(老年代)
- JDK 9 ~ JDK20: G1
- JDK 默认垃圾收集器(使用 java -XX:+PrintCommandLineFlags -version 命令查看)
- 新生代回收器
- Serial
- ParNew
- parallel
- 老年代回收器
- Serial Old
- CMS
- Parallel Old
- 新生代和老年代回收器
- G1
- Serial 收集器
- 单线程
- 新生代采用标记-复制算法,老年代采用标记-整理算法。
- 简单而高效(与其他收集器的单线程相比)
- Serial 收集器对于运行在 Client 模式下的虚拟机来说是个不错的选择
- STW
- ParNew 收集器
- Serial 收集器的多线程版本
- 新生代采用标记-复制算法,老年代采用标记-整理算法。
- 运行在 Server 模式下的虚拟机的首要选择
- 它能与 CMS 收集器(真正意义上的并发收集器)配合工作
- Parallel Scavenge 收集器
- 使用标记-复制算法的多线程收集器
- Parallel Scavenge 收集器关注点是吞吐量(高效率的利用 CPU)
- JDK1.8 默认收集器
- Serial Old 收集器
- Serial 收集器的老年代版本,它同样是一个单线程收集器
- Parallel Old 收集器
- Parallel Scavenge 收集器的老年代版本。使用多线程和“标记-整理”算法。在注重吞吐量以及 CPU 资源的场合,都可以优先考虑 Parallel Scavenge 收集器和 Parallel Old 收集器。
- CMS 收集器
- “标记-清除”算法实现的
- CMS(Concurrent Mark Sweep)收集器是一种以获取最短回收停顿时间为目标的收集器。它非常符合在注重用户体验的应用上使用。
- HotSpot 虚拟机第一款真正意义上的并发收集器,它第一次实现了让垃圾收集线程与用户线程(基本上)同时工作。
- G1 收集器
- G1 (Garbage-First) 是一款面向服务器的垃圾收集器,主要针对配备多颗处理器及大容量内存的机器. 以极高概率满足 GC 停顿时间要求的同时,还具备高吞吐量性能特征.
- JDK9 开始,G1 垃圾收集器成为了默认的垃圾收集器
- ZGC 收集器
- 与 CMS 中的 ParNew 和 G1 类似,ZGC 也采用标记-复制算法,不过 ZGC 对该算法做了重大改进。
- 在 ZGC 中出现 Stop The World 的情况会更少!
- Java11 的时候 ,ZGC 还在试验阶段。经过多个版本的迭代,不断的完善和修复问题,
- ZGC 在 Java 15 已经可以正式使用了!
OutOfMemoryError
java.lang.OutOfMemoryError: GC Overhead Limit Exceeded:当 JVM 花太多时间执行垃圾回收并且只能回收很少的堆空间时
java.lang.OutOfMemoryError: Java heap space :假如在创建新的对象时, 堆内存中的空间不足以存放新创建的对象, 就会引发此错误。(和配置的最大堆内存有关,且受制于物理内存大小。最大堆内存可通过-Xmx参数配置,若没有特别配置,将会使用默认值
方法区
方法区属于是 JVM 运行时数据区域的一块逻辑区域,是各个线程共享的内存区域。
当虚拟机要使用一个类时,它需要读取并解析 Class 文件获取相关信息,再将信息存入到方法区。方法区会存储已被虚拟机加载的 类信息、字段信息、方法信息、常量、静态变量、即时编译器编译后的代码缓存等数据。
永久代是 JDK 1.8 之前的方法区实现,JDK 1.8 及以后方法区的实现变成了元空间。
Why MateSpace ?
- 整个永久代有一个 JVM 本身设置的固定大小上限,无法进行调整,而元空间使用的是本地内存,受本机可用内存的限制,虽然元空间仍旧可能溢出,但是比原来出现的几率会更小。
- 元空间里面存放的是类的元数据,这样加载多少类的元数据就不由 MaxPermSize 控制了, 而由系统的实际可用空间来控制,这样能加载的类就更多了;
- 在 JDK8,合并 HotSpot 和 JRockit 的代码时, JRockit 从来没有一个叫永久代的东西, 合并之后就没有必要额外的设置这么一个永久代的地方了;
- 方法区常用参数
- JDK 1.8 之前
- -XX:PermSize=N //方法区 (永久代) 初始大小
- -XX:MaxPermSize=N //方法区 (永久代) 最大大小,超过这个值将会抛出 OutOfMemoryError 异常:java.lang.OutOfMemoryError: PermGen
- JDK 1.8 永久代被移除,JDK 1.7已经开始了
- -XX:MaxMetaspaceSize 标志设置最大元空间大小,默认值为 unlimited,这意味着它只受系统内存的限制。
- -XX:MetaspaceSize 调整标志定义元空间的初始大小,如果未指定此标志,则 Metaspace 将根据运行时的应用程序需求动态地重新调整大小。
- 永久代很大的不同就是,如果不指定大小的话,随着更多类的创建,虚拟机会耗尽所有可用的系统内存。
运行时常量池
- 常量池(Constant Pool)
- 常量池(Class文件常量池):.java经过编译后生成的.class文件,是Class文件的资源仓库。
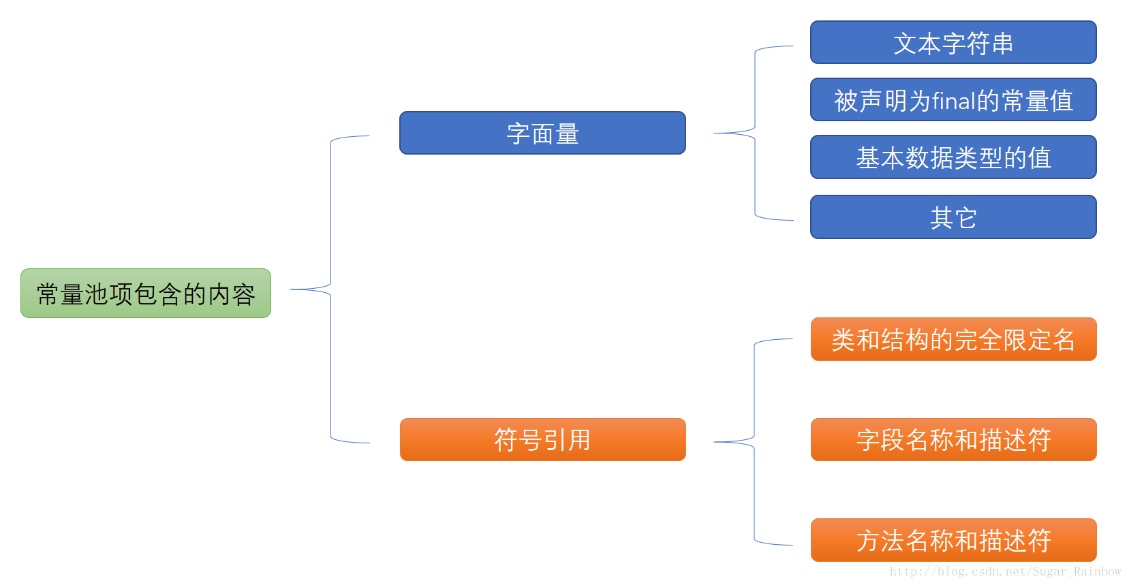
- 常量池中主要存放俩大常量:
- 字面量(文本字符串,final常量)
- 字面量是源代码中的固定值的表示法,即通过字面我们就能知道其值的含义。字面量包括整数、浮点数和字符串字面量。
- 符号引用(类和接口的全局定名,字段的名称和描述,方法的名称和描述)
- 常见的符号引用包括类符号引用、字段符号引用、方法符号引用、接口方法符号。
- 字面量(文本字符串,final常量)
- 运行时常量池是方法区的一部分
- 常量池表会在类加载后存放到方法区的运行时常量池中。
- 运行时常量池的功能类似于传统编程语言的符号表,尽管它包含了比典型符号表更广泛的数据。
- 受到方法区内存的限制,当常量池无法再申请到内存时会抛出 OutOfMemoryError 错误
字符串常量池
字符串常量池,在堆区开一段内存存放字符串, 是 JVM 为了提升性能和减少内存消耗针对字符串(String 类)专门开辟的一块区域,主要目的是为了避免字符串的重复创建;
直接内存
直接内存是一种特殊的内存缓冲区,并不在 Java 堆或方法区中分配的
通过 JNI 的方式在本地内存上分配的。
直接内存的分配不会受到 Java 堆的限制,但是,既然是内存就会受到本机总内存大小以及处理器寻址空间的限制。
直接内存并不是虚拟机运行时数据区的一部分,也不是虚拟机规范中定义的内存区域,但是这部分内存也被频繁地使用。而且也可能导致 OutOfMemoryError 错误出现。
JVM-内存参数
- 堆内存
- –Xms 最小
- -Xmx 最大
- 显式新生代内存,默认情况下,YG 的最小大小为 1310 MB,最大大小为无限制。
- -XX:NewSize 最小
- -XX:MaxNewSize 最大
- -Xmn:此设置 NewSize 与 MaxNewSize 设为一致的
-XX:NewRatio=<int>来设置老年代与新生代内存的比值- 显式指定永久代/元空间的大小
- jdk1.8之前
- -XX:PermSize=N #方法区 (永久代) 初始大小
- -XX:MaxPermSize=N #方法区 (永久代) 最大大小
- 从 Java 8 开始,如果我们没有指定 Metaspace 的大小,随着更多类的创建,虚拟机会耗尽所有可用的系统内存(永久代并不会出现这种情况)。
- -XX:MetaspaceSize=N #设置 Metaspace 的初始大小(Metaspace 的初始容量并不是 -XX:MetaspaceSize 设置,无论 -XX:MetaspaceSize 配置什么值,对于 64 位 JVM 来说,Metaspace 的初始容量都是 21807104(约 20.8m))
- -XX:MaxMetaspaceSize=N #设置 Metaspace 的最大大小
- jdk1.8之前
- 垃圾回收器
- -XX:+UseSerialGC
- -XX:+UseParallelGC
- -XX:+UseParNewGC
- -XX:+UseG1GC
- 处理 OOM
- 这些参数将堆内存转储到一个物理文件中,以后可以用来查找泄漏
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=./java_pid<pid>.hprof
-XX:OnOutOfMemoryError="< cmd args >;< cmd args >"
-XX:+UseGCOverheadLimit
- GC 日志记录
# 必选
# 打印基本 GC 信息
-XX:+PrintGCDetails
-XX:+PrintGCDateStamps
# 打印对象分布
-XX:+PrintTenuringDistribution
# 打印堆数据
-XX:+PrintHeapAtGC
# 打印Reference处理信息
# 强引用/弱引用/软引用/虚引用/finalize 相关的方法
-XX:+PrintReferenceGC
# 打印STW时间
-XX:+PrintGCApplicationStoppedTime
# 可选
# 打印safepoint信息,进入 STW 阶段之前,需要要找到一个合适的 safepoint
-XX:+PrintSafepointStatistics
-XX:PrintSafepointStatisticsCount=1
# GC日志输出的文件路径
-Xloggc:/path/to/gc-%t.log
# 开启日志文件分割
-XX:+UseGCLogFileRotation
# 最多分割几个文件,超过之后从头文件开始写
-XX:NumberOfGCLogFiles=14
# 每个文件上限大小,超过就触发分割
-XX:GCLogFileSize=50M
- 其他
-server : 启用“ Server Hotspot VM”; 此参数默认用于 64 位 JVM
-XX:+UseStringDeduplication : Java 8u20 引入了这个 JVM 参数,通过创建太多相同 String 的实例来减少不必要的内存使用; 这通过将重复 String 值减少为单个全局 char [] 数组来优化堆内存。
-XX:+UseLWPSynchronization: 设置基于 LWP (轻量级进程)的同步策略,而不是基于线程的同步。
-XX:LargePageSizeInBytes: 设置用于 Java 堆的较大页面大小; 它采用 GB/MB/KB 的参数; 页面大小越大,我们可以更好地利用虚拟内存硬件资源; 然而,这可能会导致 PermGen 的空间大小更大,这反过来又会迫使 Java 堆空间的大小减小。
-XX:MaxHeapFreeRatio : 设置 GC 后, 堆空闲的最大百分比,以避免收缩。
-XX:SurvivorRatio : eden/survivor 空间的比例, 例如-XX:SurvivorRatio=6 设置每个 survivor 和 eden 之间的比例为 1:6。
-XX:+UseLargePages : 如果系统支持,则使用大页面内存; 请注意,如果使用这个 JVM 参数,OpenJDK 7 可能会崩溃。
-XX:+UseStringCache : 启用 String 池中可用的常用分配字符串的缓存。
-XX:+UseCompressedStrings : 对 String 对象使用 byte [] 类型,该类型可以用纯 ASCII 格式表示。
-XX:+OptimizeStringConcat : 它尽可能优化字符串串联操作。
JVM-工具
- HeapDump 堆转储快照 .hprof
- Java启动程序配置
- jmap 工具生成
- jhat 分析HeapDump工具,分析完成后提供http查看服务
jstack
- 生成虚拟机当前时刻的线程快照。线程快照就是当前虚拟机内每一条线程正在执行的方法堆栈的集合.
- 长时间停顿
- 线程调用堆栈
对象
对象的创建
- 类加载检查
- new 指令
- 常量池中定位类的符号引用,检查符号引用所代表的类是否 加载,解析,初始化
- 反之需执行类加载过程
- 分配内存
- 虚拟机将为新生对象分配内存
- 对象所需的内存大小在类加载完成后便可确定
- 为对象分配空间的任务等同于把一块确定大小的内存从 Java 堆中划分出来
- 内存分配方式
- 指针碰撞
- 堆内存规整(即没有内存碎片)的情况
- 空闲列表
- 堆内存不规整的情况下
- 指针碰撞
- 内存分配并发问题
- 虚拟机采用两种方式来保证线程安全
- ?
- 虚拟机采用两种方式来保证线程安全
- 初始化零值:内存分配完成后,虚拟机需要将分配到的内存空间都初始化为零值(不包括对象头)
- 设置对象头
- 初始化零值完成之后,虚拟机要对对象进行必要的设置
- 例如这个对象是哪个类的实例、如何才能找到类的元数据信息、对象的哈希码、对象的 GC 分代年龄等信息。 这些信息存放在对象头中
- 执行 init 方法
- 执行 new 指令之后会接着执行
<init>方法
- 执行 new 指令之后会接着执行
对象的内存布局
- 在 Hotspot 虚拟机中,对象在内存中的布局可以分为 3 块区域:对象头、实例数据和对齐填充。
对象的访问定位
- 建立对象就是为了使用对象,我们的 Java 程序通过栈上的 reference 数据来操作堆上的具体对象。对象的访问方式由虚拟机实现而定,目前主流的访问方式有:使用句柄、直接指针。